Prelude
Deep in the depths of the ocean, in Bikini Bottom, there was one Club Spongebob1. High up on a tall tree, sits the clubhouse, occupied by a sponge and Patrick.
Season 3, Episode 42a. Watch the episode please.

On this fine day, Squidward exits his Moai to see these two barnacle heads laughing it up in their treehouse. Of course, there is nothing more irritating than their giggling. And when Squidward was told he wouldn’t “fit in” their club, he couldn’t take it. He had to join! And so up he went.


But once inside, he found out that, indeed, he couldn’t physically “fit in” the clubhouse and was now squished next to Bob and Patrick.


Squidward, desperate to escape, reaches for a branch and tries to pull himself down.


As he’s almost down, the branch rips apart, and the treehouse is launched into the sky (sea). The clubhouse flies through the sea and comes crashing down in the thick Kelp Forest.



Oh no, Squid is trapped. Lost. Hundreds of miles from civilization.


He starts to panic. How can he escape these two morons now?
But luckily, Squidward is part of Club Spongebob, and they have one trick up their sleeve: the Magic Conch.

The Magic Conch is here to save the day!
Squidward: You’ve got to be kidding! That is just a stupid toy! How can that possibly help us?!
SpongeBob: [gasps] Squidward! We must never question the wisdom of the Magic Conch! The club always takes its advice before we do anything!
Patrick: The shell knows all!


SpongeBob: Oh, Magic Conch Shell. What do we need to do to get out of the Kelp Forest?
Magic Conch: Nothing.
Patrick: The shell has spoken!
Squidward: Nothing?! We can’t just sit here and do nothing!
Squidward: I can’t believe you two are gonna take advice from a toy!

Just do what the Conch tells you to do
Squidward thinks he’s smarter than the Magic Conch, so he runs and runs to escape the forest, only to find out he’s running in circles and is right back at Club Spongebob. He sets up a camp with the resources he has while SpongeBob and Patrick continue to listen to the Conch.


Squidward tries to use his own thinking rather than obeying the Conch
Right as Squidward was about to enjoy his roasted sea insect, a miracle falls from the sky, right into the camp of SpongeBob and Patrick! What a gift from the Magic Conch!


The gift from the Conch has arrived!
As SpongeBob and Patrick enjoy their feast, Squidward begs to be allowed to touch the food. They inform Squid that only the Conch can approve his request. And so he asks the Conch, again and again, “may I have something to eat?”


But he didn’t give the Conch its due earlier, so the Conch only gives him a simple “no”. Squidward goes crazy as the Conch seems to be aware of his dismissal of its powers.
And then, someone cuts a path into the forest!


The Kelp Forest ranger has arrived to save Squidward!
Squidward screams in delight — someone is here to save them! But to Squid’s dismay, the ranger also has a Conch of his own.


Kelp Forest Ranger: All right, Magic Conch… what do we do now?
Magic Conch: Nothing.
SpongeBob, Patrick, and Kelp Forest Ranger: All hail the Magic Conch!


Sound Familiar?
And so they sit, in silence, in devotion to the Conch, until another miracle falls from the sky. Perhaps, if they ask the Conch again and again, it will give them the answer to their problem. Perhaps, a new version of the Conch will do better than the old one.
Whenever you have a question, don’t think, just ask the Conch. And whatever the Conch tells you, is what you should parrot to others and follow diligently.2
The Conch = a large language model (henceforth called “the model”)
But, just because it worked for SpongeBob, doesn’t mean it will work for you. There is a growing mass of people who believe the Conch will enable them to do nothing, and that good things will fall out of the sky.
The Situation
There has been a lot said over the past two decades about how electronics can sap away our thinking powers. When humans lose the ability to be bored and produce something from nothing, their mental faculties decay. I believe Cal Newport put this phenomena into the public consciousness with his book “Deep Work”3 where he discusses how electronics, especially phones, have put humans in an unprecedented situation where they can go through life and never be bored.
I started hearing about the importance of boredom from 2016 or so when Newport’s book was published. A counterpoint can be found here.
In the past two years, in addition to the phone, which can prevent even a few seconds of boredom from setting in, we now have “the model”. Whatever attention span degradation phones have caused, has been or will soon be, dwarfed by the advent of the model.
As people begin to use the model, they start by asking it a few questions about topics that they would have used a search engine for in the past. However, as model dependency grows, people begin to outsource their thinking and even thoughts wholesale to the model. I need not dwell on this point too much, since others have made it much better.4
See the article “The End of Thinking” by Derek Thompson
Bimodal Undergrads
I’ve been in the university system for a long time. Almost certainly too long. Every year, I get a sample of the current class of undergrads to examine — both from teaching classes and from advising them on research. Year after year, the mean quality of undergrads has degraded — the average undergrad is increasingly motivated by money, status, and job prospects rather than any intrinsic interest in computer science. However, this trend about averages says nothing about the extremes.
The mediocre undergrads are crashing to the level of the barely literate ones, while the elite undergrads can rival senior grad students in programming competence, inquisitiveness, and instinct. Just in the past year, I’ve seen a few truly spectacular undergrads the likes of which I haven’t seen before. They can work autonomously, ask all the right questions, learn on the fly, and somehow have enough time to be at the top of their classes and do self-driven research. I know that when I was an undergrad, I was very far below their level.
You can probably predict why this bimodal distribution has emerged and gotten more extreme recently. It’s the model.
What’s happening is that even the 80th percentile undergrads are falling victim to model dependency. The majority of undergrads are not only preempting their boredom via their phones, but they are also preempting their thoughts via the model. We often see undergrads that produce reams of code from the model, but are unable to explain what is going on, and more importantly, what are they trying to do.
The elite undergrads are always in control of their own thoughts. They use the model as just an enhanced search engine, which gives them confidence to enter new areas. Their knowledge compounds rapidly as they use the model to pull information, but use their own brains to synthesize it.
Thinking in “Embedding Space”
After talking about undergrads, I must now talk about those ‘above’ me: the professor class. If you thought professors were speaking in meaningless platitudes before, you haven’t seen anything.5 I swear, if I could peer inside the head of a typical professor, I’m sure all I would find is a vector database.
There are still some intelligent professors, but among the mediocre, the recent degradation has been extreme
I often joke that professors (and the model) think in “embedding space”. What I mean to say, is that they think as if embeddings are semantics. I can’t blame them. After all, if you ask the model, it will claim that embeddings capture semantics.
When they speak, they will put words together that appear close in the embedding space, but are actually unrelated with respect to their true semantics. This is just a matter of training data: both for the professor and the model. Without enough good quality data, embeddings will tend to just capture which words occur together, rather than how they are related. While a professor should be able to ground word semantics in reality, the model cannot, so I can give the model a pass here.
Biological Frontends for Mr. Model
What could be worse than people becoming dependent on the model? What if people became the model? Indeed, this is what I witness nowadays. Professors have become biological frontends for the model.6
I don’t mean to bash on professors too much. All professions have degraded thusly.
When a student asks for advice, the questions are forwarded to the model, and the model’s response comes out of the professor’s mouth. The professor asks the model for research ideas, and then recites its responses to their students. When reviewing papers for a conference, the PDFs are fed straight into ChatGPT Pro7, and its outputs are massaged into the HotCRP boxes.
It’s research-grade intelligence after all
Context Pollution
Models suffer from context pollution, where garbage can accumulate in its context window that distracts the model from the task its supposed to perform. Being able to tell what the relevant context is, while discarding the rest, is an essential aspect of intelligence.
If you look at the managerial class in general, they are increasingly falling victim to context pollution. They attend all kinds of useless meetings and conferences where the executive class jumbles together words that have no relation to each other. Their heads are filled with words from these continuous meetings and, when they are prompted to discuss something with their subordinates, they bring up unrelated nonsense from their context window. Buzzword speak has become more and more ubiquitous.
“Asking the Model” as Research
Day after day, I will look at my Google Scholar notifications and will see the same paper repeated 100 times. Here are some recent examples:
- VerilogMonkey: Exploring Parallel Scaling for Automated Verilog Code Generation with LLMs
- Automated Multi-Agent Workflows for RTL Design
- QuArch: A Question-Answering Dataset for AI Agents in Computer Architecture
- AutoChip: Automating HDL Generation Using LLM Feedback
- Chip-Chat: Challenges and Opportunities in Conversational Hardware Design
- RTLCoder: Fully Open-Source and Efficient LLM-Assisted RTL Code Generation Technique
- Multi-Agent Reinforcement Learning for Microprocessor Design Space Exploration
- Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
- CodeMonkeys: Monkey SWE, Monkey Do
All of these thousands of papers just amount to “asking the model” in a loop, with some scaffolding, some tool use, some “prompt engineering”, and perhaps some training data for supervised fine-tuning. Perhaps some will conduct a beam search across many samples provided to them by Mr. Model. Perhaps some will construct a new dataset from thin air, which they pose as a “benchmark”.
Of course, this LLM mania isn’t limited to computer architecture papers. We see this in all disciplines, where the ‘solution’ proposed by a paper is “asking Mr. Model”, and the ‘problem’ is whatever fake problem they invent.
Furthermore, due to the high latency of conference paper deadlines and review cycles8, by the time a paper is published, its “results” are already suspect. The authors will have run all their experiments with Mr. Model v7 and by the time the world sees their work, Mr. Model v8 has been released, and large parts of their specialized ‘prompting’ techniques and scaffolding are made obsolete.
It will usually take 6+ months from running experiments to public paper release
It is just too easy for a professor to latch onto the “ask the model” methodology and enjoy the feeling of being part of the hype. At this point, “asking the model” has become its own area of research. Why bother using the model as a productivity booster or powerful search tool to produce impactful research, faster9, when you could just ask Mr. Model to write a bunch of kernels and report that?
You will find that Mr. Model becomes useless very quickly when exploring an untouched area
My final point is that academics should work on projects that have substantial intellectual, logistical, and financial risks; risks that are so high that industry researchers would not take on such projects. What is the risk here? That Mr. Model may not always be correct? Why are academics “asking the model” when there are VCs investing billions of dollars and accepting infinite risk for startups to pursue “LLM for X”?10
I can appreciate that some academics use papers as a launching pad for a startup. That’s fine I guess
“Asking the Model” as a Course
Not only has “asking the model” become its own area of research within an engineering domain (e.g. RTL design, GPU performance engineering), but “asking the model” more generally has become an acceptable topic for courses. Let me go over three examples from Stanford, Berkeley, and Harvard.
Stanford
CS329A: Self-Improving AI Agents is being offered for the second time at Stanford.
The course will start with self-improvement techniques for LLMs, such as constitutional AI, using verifiers, scaling test-time compute, combining search with LLMs, and train time scaling with RL. We will then discuss the latest research in augmenting LLMs with tool use, code, and memory, and orchestrating AI capabilities with multimodal interaction. We will next discuss multi-step reasoning and planning problems for agentic workflows, and the challenges in building robust evaluation frameworks.
It all sounds very fancy, but it boils down to asking the model in a loop. I believe this paper (The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery) is emblematic of the method being promoted. If this method can produce ‘papers’ that are so ‘high-quality’ that even humans would accept them to a ML conference, then we should be questioning the value of what humans are working on.
With that being said, the reading list for this class isn’t bad at all. These papers are interesting and worth skimming just to understand the state of the field. All I ask is that the students don’t make their class projects about getting Mr. Model to solve some problem.
UC Berkeley
CS294: Disrupting Systems Research with AI is being offered for the first time at UC Berkeley.
We are now at the beginning of a significant shift, where a new class of AI tools can autonomously generate algorithms that match and sometimes exceed the best human-designed solutions.
This course explores the frontiers of this new methodology, examining the future role of the researcher as a “strategic advisor” who guides powerful AI assistants rather than manually engineering solutions.
This is quite similar to the Stanford class, albeit a bit more hyped up. The proposed methodology boils down to “vibe research”. Ask the model to propose grand changes to some existing codebase. Then, ask the model to produce some code to manipulate a repo and see what happens. Just go with the flow.
“The shell knows all! The shell has spoken!” — Patrick Star
Harvard
And now, this is the most egregious example of model-brained nonsense by far.
Presenting, CS249r: Architecture 2.0, being offered at Harvard for the first time. I urge the reader to read the “blog posts” on the website, such as: “Week 2: The Fundamental Challenges Nobody Talks About”. It is very obvious that all these “blog posts” are written by Mr. Model. In fact, the entire website is generated by Mr. Model.

I couldn’t have said it any better myself. See the class slides.
This class is about a concept that Prof. Vijay Janapa Reddi has coined: “Architecture 2.0”. All this boils down to is generating tons of “data”11, training some models on that data, and hoping for the best. After all, if this method has yielded good results in image classification and English emission, then surely the same method will yield fruit in computer architecture. It’s just a matter of more and more data, and more and more compute: this is the “Bitter Lesson” at work.
“Data” includes random RTL designs, gate-level netlists, PPA estimates, instruction traces and so forth: the “corpus” of computer architecture.
Astute readers will note that Reddi’s “Architecture 2.0” is just a ripoff of Andrej Karpathy’s “Software 2.0”. But recently, at YC’s “AI Startup School”, Karpathy presented his talk, Software Is Changing (Again), where he coined “Software 3.0”!

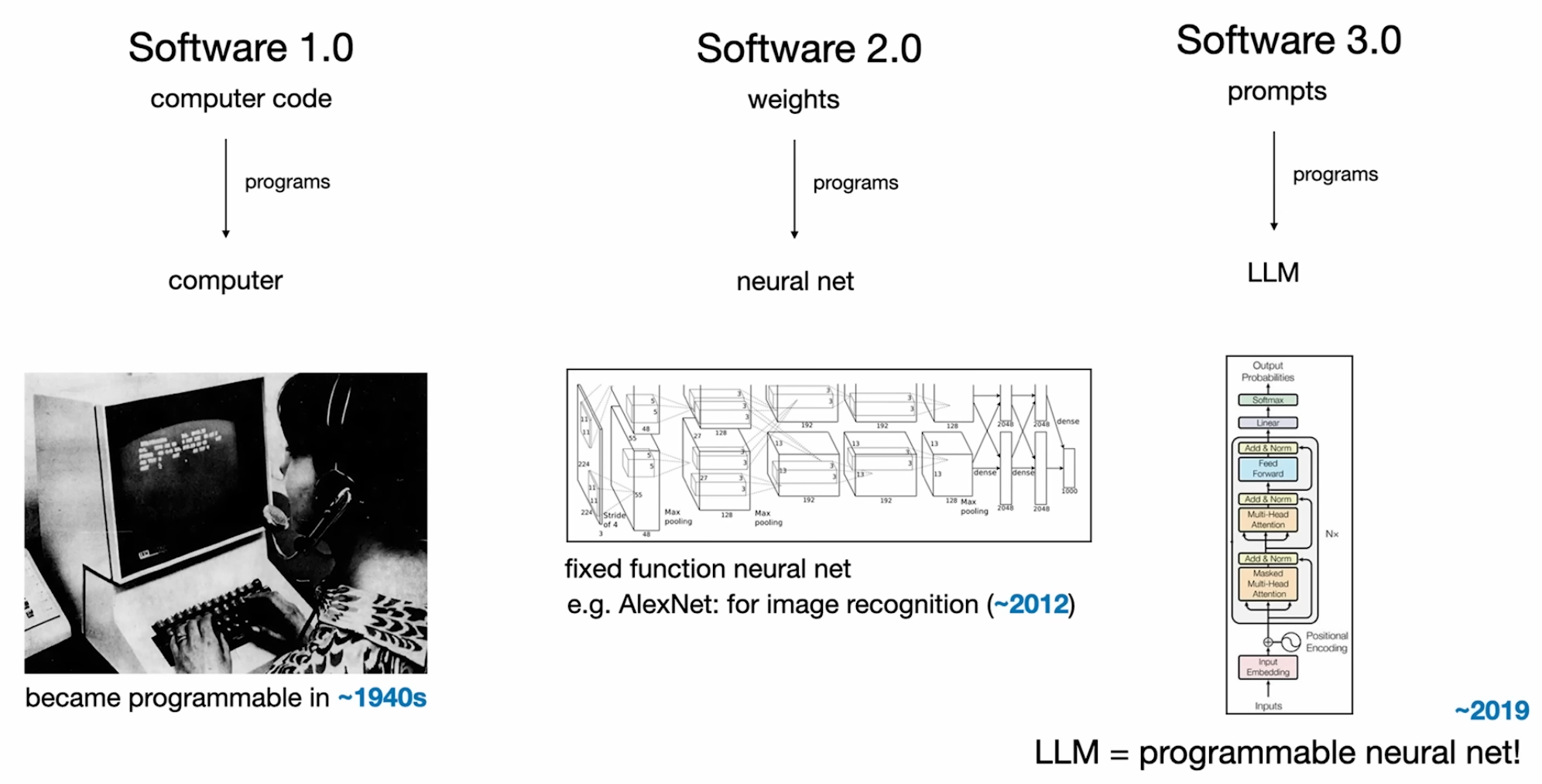
Karpathy’s slides on Software 3.0
So, Prof. Reddi, Architecture 2.0 has already been superseded! It should be time for Architecture 3.0: aka “ask the model”.

Model-generated text that contrasts Architecture 1.0 with 2.0 (actually Architecture 3.0)

Architecture 3.0 methodology in practice. Ask the model (in a loop).
I have collected many model-isms from Prof. Reddi’s course and placed them in the addendum of this article.
A Better Path
As was discussed before, the focus should not be on asking the model and evaluating how it does, but rather on using the model to build better software. I recently saw a good example of this from Mark Ren’s group12 called SALUTION: Autonomous SAT Solver Evolution. They aren’t presenting “asking the model” as the goal itself, but instead asking the model to produce a better SAT solver, which is the main contribution. They can discuss the specific elements of the code that the model generated to produce a faster solver. The focus is on the product, not the model.
Mark Ren and his team at NVIDIA Research are one of the few competent actors in the field of “ML for CAD”
Our new framework, SATLUTION, autonomously evolves Boolean Satisfiability (SAT) solvers via LLM agents that outperformed the 2025 SAT Competition champions by more than 10%
It would be good if more work like this was done. Work as a domain expert who is trying to improve some algorithm or work on a specific problem and use the model (who cares how you’re using it) to help you make things better.
Another recent example is the paper “ASPEN: LLM-Guided E-Graph Rewriting for RTL Datapath Optimization”. Here, e-graphs are used to perform word-level datapath optimization, which is usually done by hand for arithmetic circuits. The LLM is used to generate additional rewrite rules for the e-graph engine and prioritize them based on PPA feedback from the CAD tools. This process, which would normally require human intervention, is done autonomously, and it produces improved results over a static rewrite rule set. While I believe it would be better to fold back these improvements into more robust abstractions in the e-graph engine, I can appreciate that the model did do something cool.
Conclusion
Just as one should hesitate when picking up their phone to mitigate a moment of boredom, one must hesitate before shooting a query at the model. Think! Losing your boredom is bad enough, but losing your sovereignty is even worse. There is a huge risk that biological general intelligence will dry up way before AGI can come on the scene to save us.
But, you know what? Perhaps I’m wrong. Perhaps “asking the model” is the most useful, impactful, and important thing we can all do today.
In the next few years, I may be the one saying:
Squidward: All hail the Magic Conch

Response to Objections
I appreciate criticism of anything I wrote in this article. Just email me.
Let me begin by saying this article is not a formal academic argument, as it should be clear. It is just a rant. However, if I were to distill the article into some statements I believe in, here are a few:
-
Do not use the model as a substitute for thinking or learning. You want to be a domain expert. You want the ability to produce insightful thoughts. Use the model as a search and exploration tool to get to that point first. Only then, can you can begin to use the model as the creator / editor of a codebase (or a piece of writing, or so forth).
-
Academics should be careful about what they work on to avoid getting on a hype train they aren’t capable of riding. Academics aren’t rich, both in terms of free cash and GPU capital. The risks that academics take should be wholly different than those taken by VCs or megacap corporations.
-
The model is powerful. It’s getting more powerful every month. You would be a fool to dismiss the power of the model and not use it altogether.
Now, I’ll discuss some objections to this article and give my responses.
Agents are Hard
Agents are not as trivial as you make them out to be. They aren’t just a combination of prompts, RAG, fine-tuning, tool calling, tool output post-processing, beam search, hardware / profiler feedback, and so forth, in a big loop.
If you look at SOTA agents like Cursor, Claude Code, Codex CLI, Cline, Windsurf, Aider, Devin, and so forth, they are growing in complexity, rather than their scaffolding being subsumed by the base model. In fact, as the models become more powerful, and their tool calling abilities improve, the scaffolding may have to become more complex to accommodate these new abilities.
I agree that reliable agents are hard to build, and I do not want to take away from the valuable engineering and research efforts invested in these agents. However, I believe that to do good work in the area of agent architecture / optimization / sampling, one needs to have real use cases and evaluation criteria, beyond just the published “standard” benchmarks (e.g. SWE-Bench). Furthermore, agent architecture research is very expensive when it comes to running evals for each proposed change.
All of this is to say, that if one wants to pursue research in this area, they should either (1) go to Anthropic, Cognition, or the like and work on real problems or (2) take the VC money that is freely flowing and build a domain-specific agent or (3) contribute to open source agents such as Aider.
I believe it isn’t reasonable to do coding agent work in academia anymore — it was reasonable for a short period of a year or so, but today the resources needed to make a dent are too substantial. Academics are flooding this area because (in my opinion), it feels easy to pick a niche domain and build an agent for it that outperforms some stale baseline on a niche benchmark. I have to say though that I’m a fan of DSPy and I think work along this line should be pursued by academics.
“Asking the Model” Does Work
As the readings from these classes have shown, asking the model does indeed work to optimize existing software or even propose new research ideas, produce evaluations, and write an entire paper that passes scrutiny by humans. You pointed out research on optimizing SAT solvers using LLMs — this is another example of the model being able to produce useful outputs given the right scaffolding.
How can you claim that “asking the model” should be avoided, when we can see that is does yield fruit? How can you claim that academics shouldn’t pursue agent engineering research when it’s about how to leverage LLMs effectively to improve software / systems?
Firstly, I agree that the “asking the model” does often produce good results, and that the right scaffolding around the model greatly impacts the quality of its results. However, I do believe that some discretion is needed here with regards to choosing the right problem to work on and leveraging existing agentic frameworks vs rolling your own. My point is that the result of domain-specific research should be the product rather than the model loop that is used to create the product.
Furthermore, it is much more valuable to build something using the model and report how it went via a blog post rather than evaluating some bespoke agent you built on some benchmark and publishing the results for them to only arrive 6 months in the future. Here is a good example: Vibing a Non-Trivial Ghostty Feature. More examples can be found on Simon Willison’s blog such as “Getting DeepSeek-OCR working on an NVIDIA Spark via brute force using Claude Code”.
Lastly, I believe that domain knowledge is crucial when it comes to building the right scaffolding, choosing a good problem, and picking a strong baseline to compare against. Building that domain knowledge should be the priority for anyone entering a domain. Asking the model without understanding the domain is vibe research, and should be avoided.
The Magic Conch is not an LLM
Your analogy is bad. The magic conch is similar to a magic 8 ball: it can’t give sophisticated answers to questions, but rather just picks random phrases from a pre-programmed list. The Conch doesn’t consider the context of the question you ask it, it doesn’t possess a world model, and it cannot use tools to prepare its answer.
In contrast, Mr. Model is a very powerful statistical token generator trained on a massive corpus of world knowledge that has common sense and can reason. How can you claim these two things are equivalent, when they are so obviously not?
Mr. Model is certainly more sophisticated than the Conch, there can be no doubt. However, the comparison has more to do with how the Conch is used rather than what it says. Uncritically taking the Conch at its word, following its instruction as if it came from the Gods, and delegating every question you have immediately to the Conch are the problems. Finally, for academic researchers, leveraging the Conch to do interesting things is far more valuable than sweeping the space of using the Conch.
Don’t take this analogy too seriously.
Barbarians at the Gate
Shortly after I published this article, a whitepaper was published on arXiv on October 7th titled “Barbarians at the Gate: How AI is Upending Systems Research” by the Berkeley Sky Lab professors (Koushik Sen, Matei Zaharia, Ion Stoica, …). This whitepaper argues that “asking the model” works, is effective, and should be the basis for what they term “AI-Driven Research for Systems”.
Given a task, the typical AI-driven approach is (i) to generate a set of diverse solutions, and then (ii) to verify these solutions and select one that solves the problem.
We argue that systems research, long focused on designing and evaluating new performance-oriented algorithms, is particularly well-suited for AI-driven solution discovery.
We term this approach as AI-Driven Research for Systems (ADRS), which iteratively generates, evaluates, and refines solutions.
We then discuss the broader implications for the systems community: as AI assumes a central role in algorithm design, we argue that human researchers will increasingly focus on problem formulation and strategic guidance.
The traditional model of systems research involves finding some problem in an existing codebase and then hacking on it until you get a sufficiently good solution that warrants a paper.
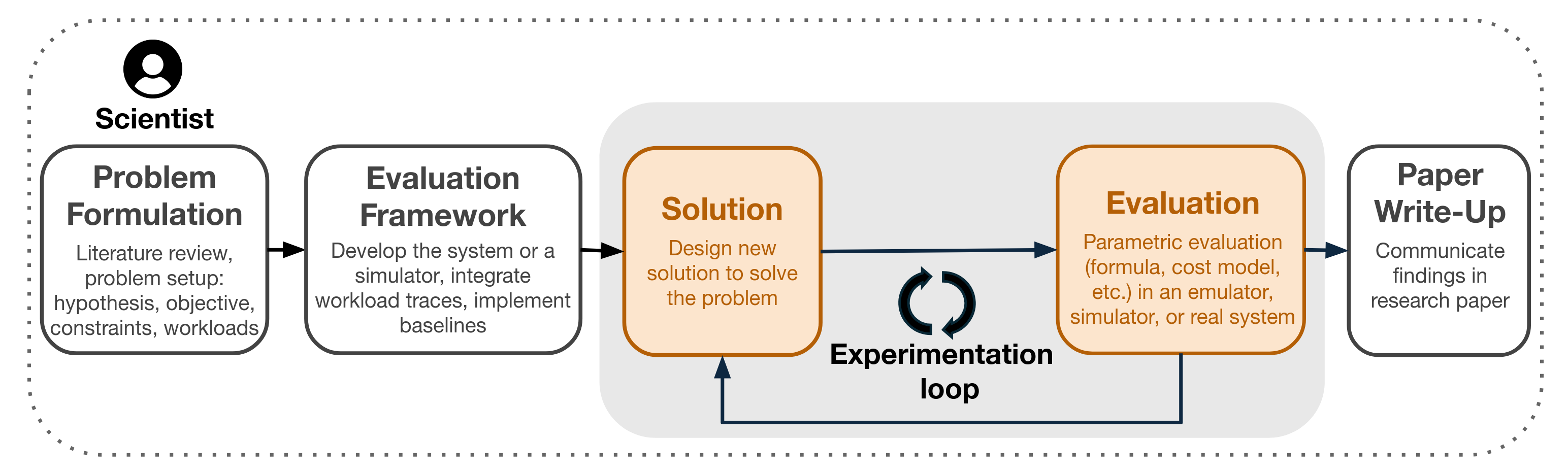
The ‘typical’ methodology of systems research.
The whitepaper proposes a way to automate the most time-consuming part of systems research: the process of editing code and tuning / sweeping / evaluating.
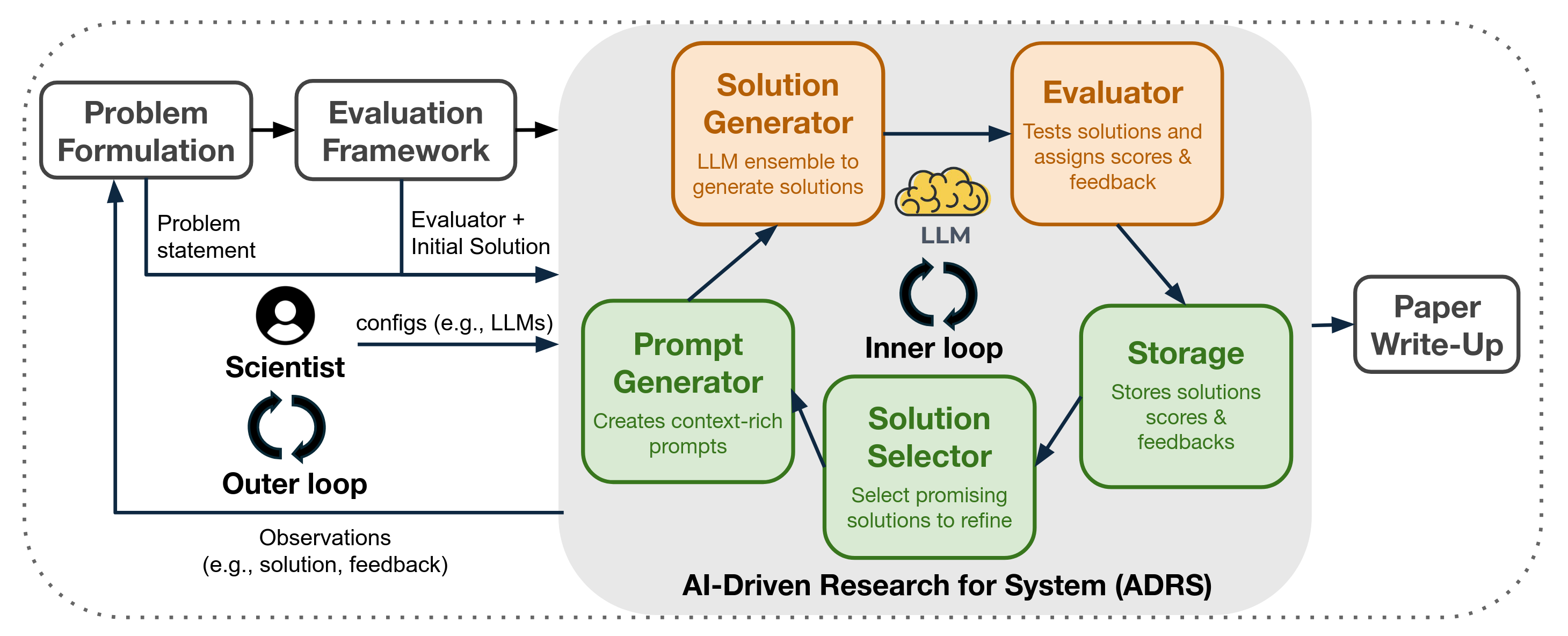
AI-Driven Research for Systems (ADRS) is, quite unambiguously, ‘ask the model’ (in a loop).
ADRS involves asking powerful agents to edit / evaluate code iteratively using a genetic algorithm to guide the search process (ala AlphaEvolve, OpenEvolve, GEPA).
The argument the whitepaper uses to justify “ADRS” goes like this:
- Systems research is about finding a bottleneck or sub-optimal algorithm in a software/hardware stack (e.g. compilers, runtimes, schedulers, hardware tuning knobs) in order to improve some application’s performance
- The model is very good at editing code, performing search, and mixing algorithms/heuristics from the literature in a novel way. The code that the model needs to edit is often localized to a few files (e.g. app-level scheduler algorithm tweaks).
- It is easy to evaluate the impact of the model’s edits reliably and quantitatively with respect to correctness and performance characteristics (e.g. memory usage, latency, throughput). Evaluation can be done using performance simulators and/or real systems.
- The model is getting cheaper and is able to maintain coherence across longer time horizons than before. The cost to ask the model thousands of times to solve a problem is marginal compared to the cost and time for a human to implement optimizations in a codebase.
Therefore: Asking the model is a suitable and effective way of conducting systems research. Humans should focus on guiding the agent and formulating useful problems to solve.
My Opinion
At first glance, everything here seems reasonable. I would say that their argument is airtight, except for the first premise.
What is Being Argued For?
Here is the sentence from the whitepaper that I paraphrased into the first premise:
In this paper, we advocate an AI-driven approach to systems performance problems. While performance optimization is not the only focus of systems research, it remains a central one—a brief survey of top systems, networking, and database venues (NSDI, OSDI, SIGMOD, SOSP, and VLDB) shows that over one-third of published papers feature performance optimization algorithms as their core contribution.
The authors concede that not all of systems research can be boiled down to performance optimization. However, for the sake of argument, and since ADRS is most suitable for it, let’s first examine the case of performance optimization systems research.
In this case, I would argue that the paper has already been written before any work has been done. The researcher has found a problem (i.e. bottleneck, performance pathology) in an existing system that he knows is solvable (i.e. amenable to optimization) using the typical techniques used in the field (e.g. better heuristics, more suitable data structures, speculation). It is just13 a matter of doing the profiling and implementation to show that an improvement has been made and to characterize how significant it is.
I don’t mean to trivialize the difficulty of implementation, but it is often mechanical in nature (which is why ADRS can work)
In the case of ADRS, the situation is even more extreme — the solution is known even before the problem has been specified. The solution being, “ask the model”.14 Perhaps the details of prompting, test-time scaling, and Monte Carlo tree search aren’t known in advance, but this doesn’t change the fact that the model is primal in ADRS.
“Asking the model” is a solution in search of a problem, a ‘solution-oriented’ problem.
Why Can’t We Go All the Way?
Consider this statement from the whitepaper:
In the broader context of AI-driven research, our focus is deliberately narrow. Not only do we restrict our scope to the systems domain, but in this context, we focus only on the task of solution discovery, while largely ignoring other aspects in the research process, like problem formulation, literature survey, or paper writing.
ADRS is focused on the task of writing / editing code (which they term “solution discovery”), while the other aspects of the research process (problem identification, setting up the model’s scaffold, writing a paper) are left in the hands of humans. But if we were to consult the charts, it seems that Mr. Model can take over these other aspects too, very soon.
Why can’t the last step (“Paper Write-Up”) be done agentically? This is often the most mechanical and uninspiring part of the research process. We can even “close the loop” by having the model come up with new problems to solve on its own — this is just a matter of search over existing code and literature + profiling production machines.
The argument for ADRS, taken to its logical conclusion, would end up turning systems research into a fully model-driven paper pumping machine. Arguably, systems research in its current form is already a human-driven paper pumping machine. We can already see the first inklings of ADRS transitioning the paper machine from being human to model driven.15
This methodology has been put into action by Sakana AI
What Should Academics Do?
Even if we were to concede that ADRS is a good research methodology, what exactly does this process produce? In the best case, it produces a system (e.g. an application server, inference service, load balancer, workload scheduler) that is slightly more optimized than what already exists.
This form of research is justifiable and undoubtedly valuable for a large hyperscaler such as Google: see their paper “ECO: An LLM-Driven Efficient Code Optimizer for Warehouse Scale Computers”.
They show the model many historical examples of performance anti-patterns and their fixes, and then ask the model to find additional opportunities in the google3 codebase.
The model autonomously makes the right code edits, checks that its changes are valid with existing unit/integration tests, makes a PR for a Googler to review, and once deployed in production, the model-written code is monitored to validate its correctness and characterize its performance improvement.
Currently deployed on Google’s hyperscale production fleet, this system has driven >25k changed lines of production code, across over 6.4k submitted commits, with a >99.5% production success rate. Over the past year, ECO has consistently resulted in significant performance savings every quarter. On average, the savings produced per quarter are equivalent to over 500k normalized CPU cores.
How can anyone argue with this? Indeed, I must concede that this work is valuable and impactful.
While we should be impressed by this research, we should also ask, “is this what academics should be doing”? It makes sense for a hyperscaler to optimize every bit of code they can, where even a tiny performance optimization makes a significant impact on the scale they operate at. But does it make sense for an academic research lab to do the same?
I would argue the answer is no. For one, academics should be prototyping new systems rather than making nit optimizations to existing ones. If academics are relegated to doing the same work as industry research labs, but on open source repositories, it begs the question as to why academics exist in the first place. Where is the risk in ADRS? Do something the industry players can’t do!
What is Systems Research?
Let’s go back to the original point I made about the first premise being fishy. As the authors concede, systems research is not just about finding some bottleneck and alleviating it with the right code edits (“performance optimization”). If ADRS picks up steam and begins to dominate the conference proceedings, which I suspect it will, it will crowd out the other, more interesting, aspects of systems research.
I claim that the most impactful and interesting systems research projects involve building completely new libraries, tools, abstractions, programming models, compiler infrastructures, and paradigms. Let me illustrate by example.
Just from the lab of the ADRS authors, came these wildly successful projects: Mesos (which led to its modern incarnation, Kubernetes), Spark (which pioneered modern data processing abstractions and was commercialized as Databricks), Ray (which is widely used for distributed AI jobs, arguably a successor to Spark, and was commercialized as Anyscale), and Skypilot (which implements a “cloud-neutal” abstraction layer and will certainly be commercialized soon).16
Other impactful systems projects: ML (TensorFlow, PyTorch, JAX, MLIR, Triton), data (Dask, Polars, DuckDB), infra (gRPC, Terraform, Kafka, Nix), databases (Cassandra, RocksDB, ClickHouse)
While these projects are arguably too industrial and commercialization-focused for academic research, their impact can’t be understated. Impactful systems research involves building real systems and new abstractions, and free-form exploration of some unknown space. Can the ADRS methodology alone produce high impact academic research? It seems unlikely.
Addendum
With all the argumentation out of the way, it’s time for fun. I’ll use this section to write about some funny model-isms from Prof. Vijay Janapa Reddi’s CS249r (Architecture 2.0: Agentic AI for Computer Systems Design) website.
Reddi’s Agents
Reddi uses a “discussion agent” that writes ‘discussion questions’ to be discussed in class.
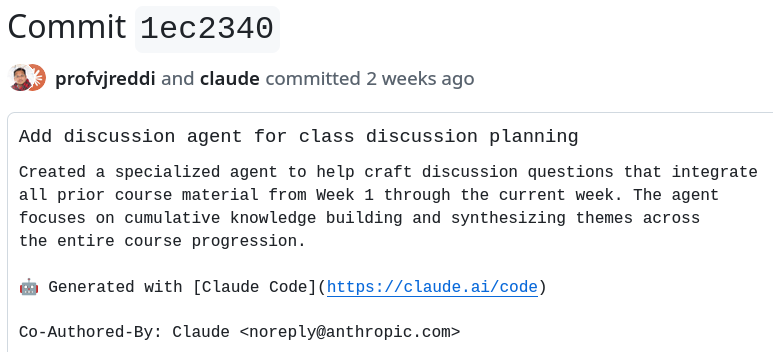
I’m sure the students will appreciate an agentic discussion.

The students shouldn’t bring AI-generated responses to the AI-generated discussion
Reddi uses a “blog writer agent” that provides “editorial feedback”.

Mr. Model, please ‘present the draft blog post to the instructor’
The “blog writer agent” needed some coaxing to not produce text that was too easily attributable to Mr. Model.

Mr. Model, ‘AVOID LLM Writing Patterns’. It didn’t work 😆
The “blog writer agent” knew that Claude was the actual author of the model-generated prose, so Reddi had to patch that too.

Mr. Model, don’t attribute yourself as the author!
When faced with a moral quandary about authorship, it is best to ask the model. The model’s opinion is on Reddi’s syllabus of course.

Transparent attribution: When AI significantly contributes, acknowledge it. How about it Reddi?
I will remind the reader that Prof. Vijay Janapa Reddi is a tenured associate professor at Harvard University. Undergraduates pay Harvard $59k in tuition every year to be “taught” by biological model frontends like Prof. Reddi.
The Model Goofs Up
Look at the “Week 5” section of the syllabus.

Near the bottom, do you see the paper that’s supposedly titled “Reinforcement Learning for FPGA Placement”? Why is that there? Isn’t this section supposed to be about “GPU Kernels and Parallel Programming”?
If you look at the linked paper it’s actually titled: “Dynamic minimization of bi-kronecker functional decision diagrams”. So it seems Mr. Model just put some random paper in the reading list that seemed close in the embedding space.
The great irony, is that on the syllabus page, the model has already warned about itself!

“Verify everything”, right? But it seems the professor himself is incapable of using GenAI effectively. The model is more aware than the people using it.
The Model Cleans Up Model-Generated Text
See this commit where Reddi uses Mr. Model to remove model-isms from the “blog posts”, such as em dashes and hyphenated words.

Mr. Model, please don’t use em dashes. It’s too embarrassing. Use colons instead.
In this commit, Prof. Reddi uses Claude Code to “polish” a verbose “blog post” likely originally created by Gemini or GPT (or perhaps Claude without the “avoid LLM writing patterns” instruction).
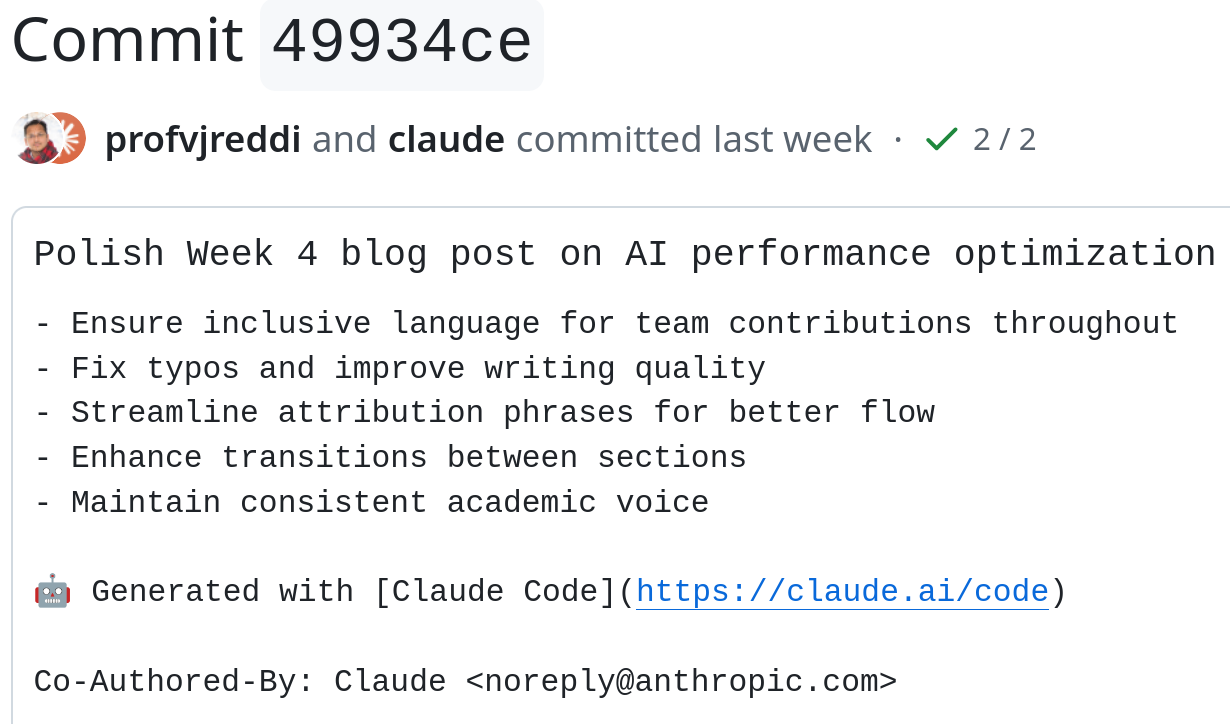

Mr. Model ‘polishes’ its own text. Slop → slop.
The Model Goofs Up Again
As the model was removing model-isms from its own text, it also made a mistake!

Mr. Model goes schizo and edits a correct link for no reason
It inadvertently updated the link of the ECO paper to a random paper titled “Positivity Bounds on Massive Vectors”. I didn’t know that Reddi was so interested in high energy physics! The incorrect link to the ECO paper is still up on the Week 4 blog post.
Thinking in Embedding Space
Take a look at Prof. Reddi’s latest model-generated “blog post”: Week 5: From CPU Transparency to GPU Complexity - The Performance Engineering Frontier.
There is one section that is quite revealing:

maintaining low latency in the prediction process is crucial for AI coding assistants
OK sure. Cursor has to optimize for low time-to-first-token to please its typical user when not operating in agent mode (e.g. tab completions, directed code edits, code analysis).
He noted that the cost of efficient inference scheduling, both for rollout generation and reward computation, often dominates the training pipeline. This observation captures a fundamental tension in production AI systems: the very optimizations that make training efficient can create bottlenecks during inference
So perhaps inference can dominate the total runtime of an RL pipeline. But why would any training optimizations affect the performance of the model when just running inference?
While research systems can afford to spend significant time optimizing kernels offline, production systems must balance optimization quality against response time.
What? Kernel optimization is almost by definition done offline. Why would a “production system” have to “balance” anything? Why is “response time” important when you’re optimizing a GPU kernel? Even if we were to concede that TTFT makes an agentic optimization loop run faster, it is still throughput-bound.
This is a great example of the model thinking in embedding space. It first notices that “low latency” is important in interactive LLM applications. Then it jumbles up the meaning of the word “latency” in different contexts in the subsequent paragraphs and produces unintelligible slop that sounds like a deep insight.
Let’s Ask the Model
Of course, I had to check if the model could understand what I mean by “thinking in embedding space”. After placing the right embeddings in its context window, it began to “understand”.


GPT5 does a good job explaining the concept of ‘thinking in embedding space’
Funnily enough, GPT kept suggesting that it could follow up with mocking quips about “thinking in embedding space” — perhaps it is too tuned to my style of conversation.


GPT5 is very eager to mock. AI safetyists must be concerned.
An Agentic Textbook
Prof. Vijay Reddi has become quite confident in the ability of the model. Now, he is just asking Claude Code to rewrite huge swaths of his textbook “Machine Learning Systems: Principles and Practices of Engineering Artificially Intelligent Systems”.
For instance, take a look at this commit which had Claude Code rewrite thousands of lines of prose, all at once.

What is the chance he reviewed these changes personally, one-by-one? Consider that the next massive commit from Claude is pushed just an hour after this one.
Of course, nothing is being reviewed. We are now also in the era of “vibe writing” — Mr. Model produces mountains of verbose and meaningless prose that goes into a textbook. The undergrads better get used to it.
Mr. Model, Don’t Reveal Yourself
In October 2025, Reddi asked the agents to clean up after themselves both in his textbook repo and CS249r website repo.
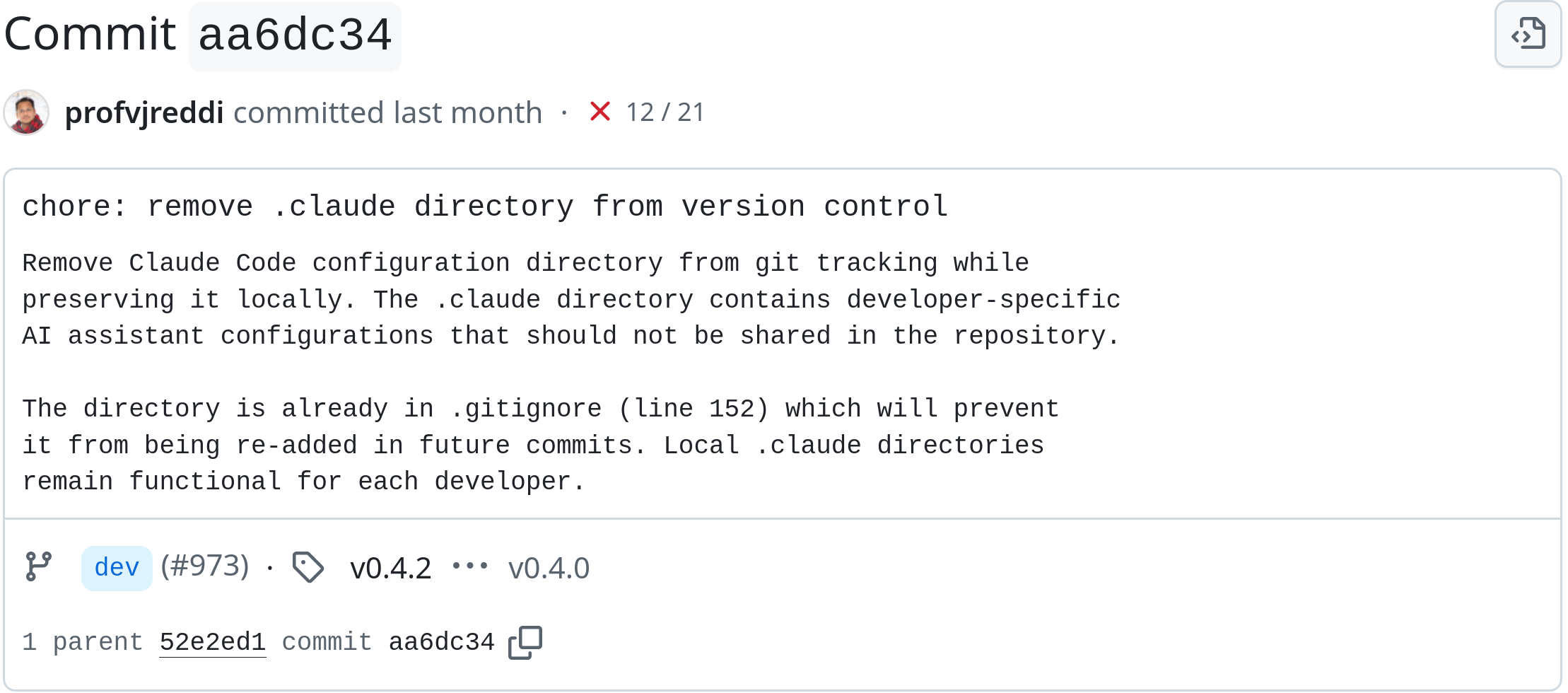
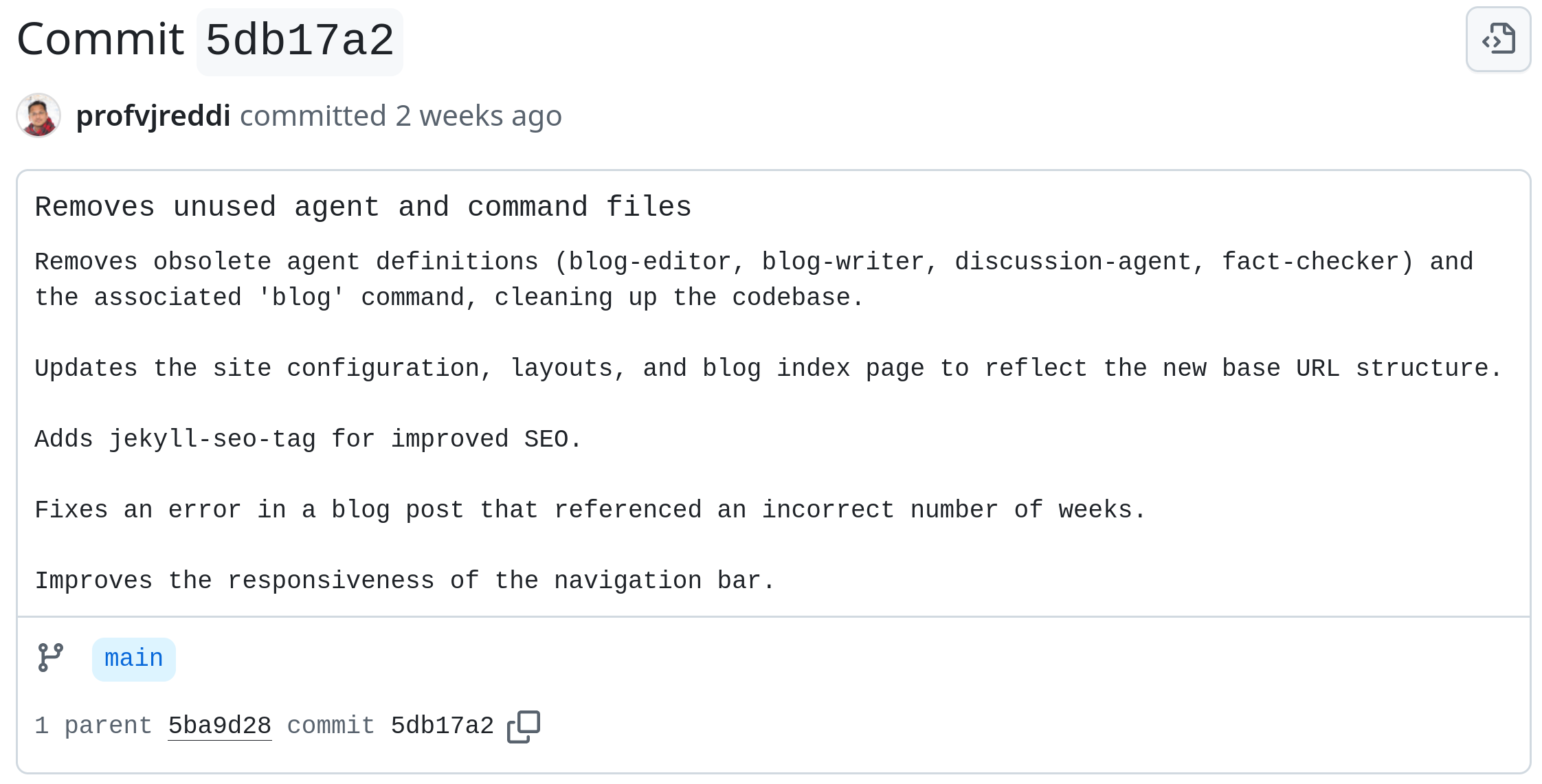
Delete .claude please, that wasn’t supposed to be committed
Of course, that didn’t stop the latest “blog post”, “Week 9: Can AI Master Predictive Reasoning? Designing for Patterns You Can’t See”, from being completely model generated.
How do you design systems to predict the unpredictable?
This isn’t just an engineering challenge. It’s a question about the nature of prediction itself.
Thanks for the insight Mr. Model!
The Model Won’t Listen!
It’s been 9 weeks of agentic blog posts, but the model still won’t listen to Reddi! He has already asked it over and over to quit it with the LLM writing patterns. All his prompting didn’t work — he had to request the em dash purge manually.
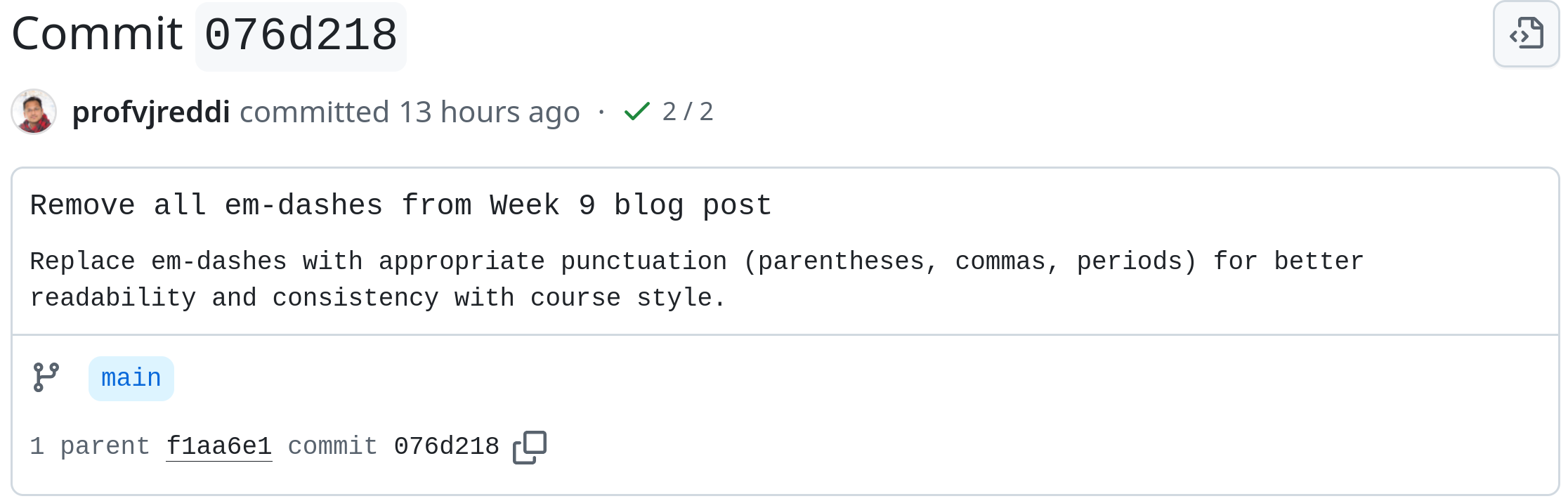

Mr. Model, please remove those em dashes again 😞. Let’s use parentheses instead.